Dynamic 3D Gaussian Tracking for Graph-Based Neural Dynamics Modeling
We propose a novel approach for learning a graph-based neural dynamics model from real-world data. By using videos captured from robot-object interactions, we achieve dense 3D tracking with a dynamic 3D Gaussian Splatting framework. Training a graph-based neural dynamics model on top of the 3D Gaussian particles enables action-conditioned video prediction and model-based planning.
3D Tracking
Action-Conditioned Video Prediction
3D Tracking with Large Occlusions and Deformations (Rebuttal)
We perform additional 3D tracking experiments in the rebuttal to demonstrate the robustness of tracking with significant occlusions and deformations.These experiments show various cloth-folding actions with different cloth and 3D rope manipulation, which introduce large deformations and occlusions, including self-occlusions.
3D Tracking with Shadows (Rebuttal)
We perform additional 3D tracking experiments in the rebuttal to demonstrate the robustness of tracking with significant shadows.These experiments show the tracking performance of manipulation of cloth and rope with large shadows.
More Examples (Rebuttal)
We show the tracking performance on more examples. We manipulate the stuffed goose with different parts and show the tracking results.
Abstract
Videos of robots interacting with objects encode rich information about the objects' dynamics. However, existing video prediction approaches typically do not explicitly account for the 3D information from videos, such as robot actions and objects' 3D states, limiting their use in real-world robotic applications. In this work, we introduce a framework to learn object dynamics directly from multi-view RGB videos by explicitly considering the robot's action trajectories and their effects on scene dynamics. We utilize the 3D Gaussian representation of 3D Gaussian Splatting (3DGS) to train a particle-based dynamics model using Graph Neural Networks. This model operates on sparse control particles downsampled from the densely tracked 3D Gaussian reconstructions. By learning the neural dynamics model on offline robot interaction data, our method can predict object motions under varying initial configurations and unseen robot actions. The 3D transformations of Gaussians can be interpolated from the motions of control particles, enabling the rendering of predicted future object states and achieving action-conditioned video prediction. The dynamics model can also be applied to model-based planning frameworks for object manipulation tasks. We conduct experiments on various kinds of deformable materials, including ropes, clothes, and stuffed animals, demonstrating our framework's ability to model complex shapes and dynamics.
Method
We first achieve dense 3D tracking of long-horizon robot-object interactions using multi-view videos and Dyn3DGS optimization. We then learn the object dynamics through a graph-based neural network. This approach enables applications such as (i) action-conditioned video prediction using linear blend skinning for motion prediction, and (ii) model-based planning for robotics.
Video with Audio
More Results
3D Tracking
We demonstrate point-level correspondence on objects across various timesteps, highlighting precise dense tracking even under significant deformations and occlusions. Our 3D tracking method demonstrates superior performance across all object instances, effectively handling diverse scenarios, interactions, and various robot actions and contact points. This showcases the capability of our approach to accommodate different physical properties and interaction dynamics by using various physical principles as optimization objectives for tracking.
Action-Conditioned Video Prediction
Our method demonstrates high-quality alignment with the ground truth contours compared to the MPM baseline, indicating a more accurate modeling of object dynamics. This accuracy enables more realistic and physically accurate video prediction. For example, over time, the MPM baseline increasingly deviates from the ground truth when manipulating the rope, and the behavior of the cloth fails to align with real-world physics. Our method maintains fidelity to the actual dynamics, ensuring more precise and reliable predictions.

Model-Based Planning
We select tasks such as rope straightening, cloth relocating, and toy doll relocating to showcase our model’s capability to manipulate highly deformable objects to target configurations. Our approach consistently maintains low errors within a limited number of planning steps and achieves a high success rate under stringent error margins. This highlights the effectiveness and precision of our method in handling diverse manipulation tasks. The qualitative results of model-based planning on various objects further illustrate that our framework accurately learns object dynamics, ensuring reliable and efficient performance.
Rope Straightening
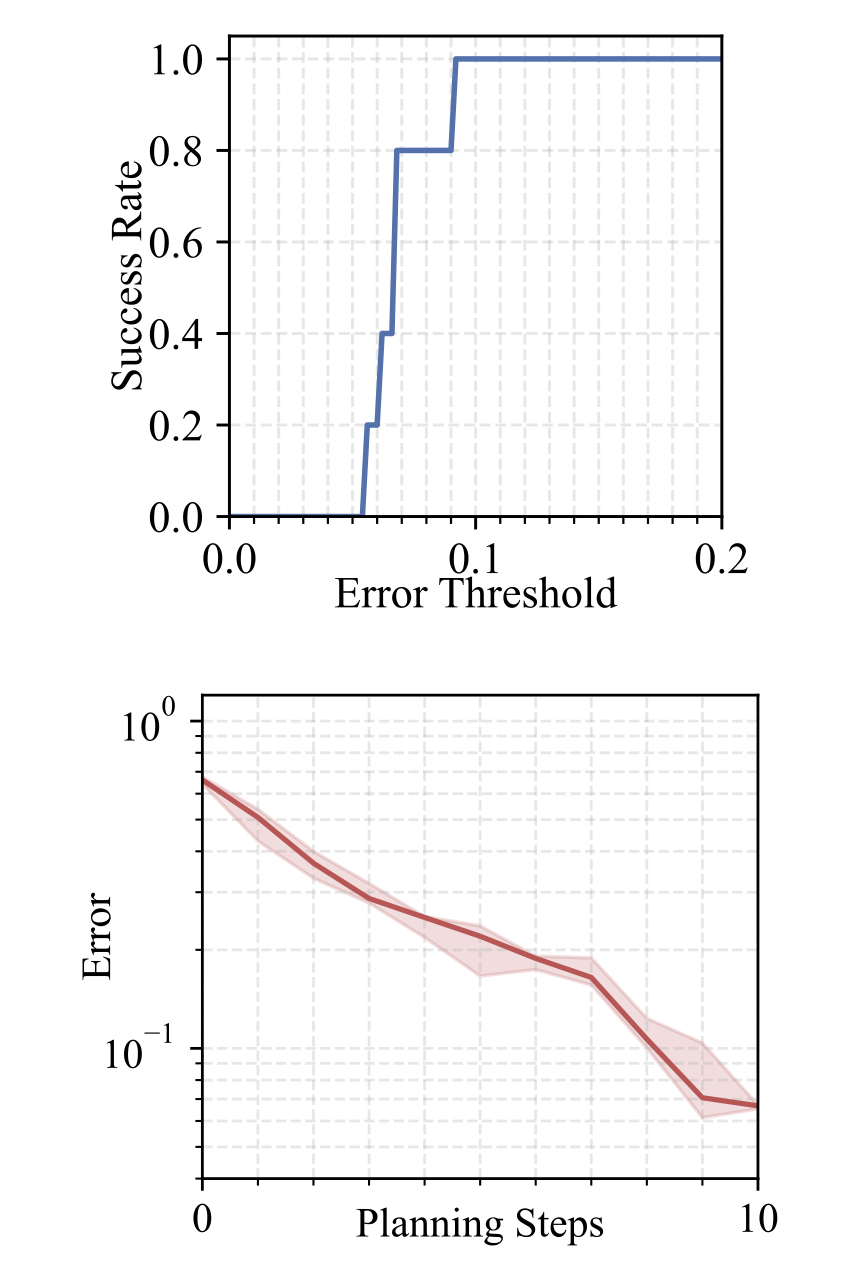
Toy Doll Relocating
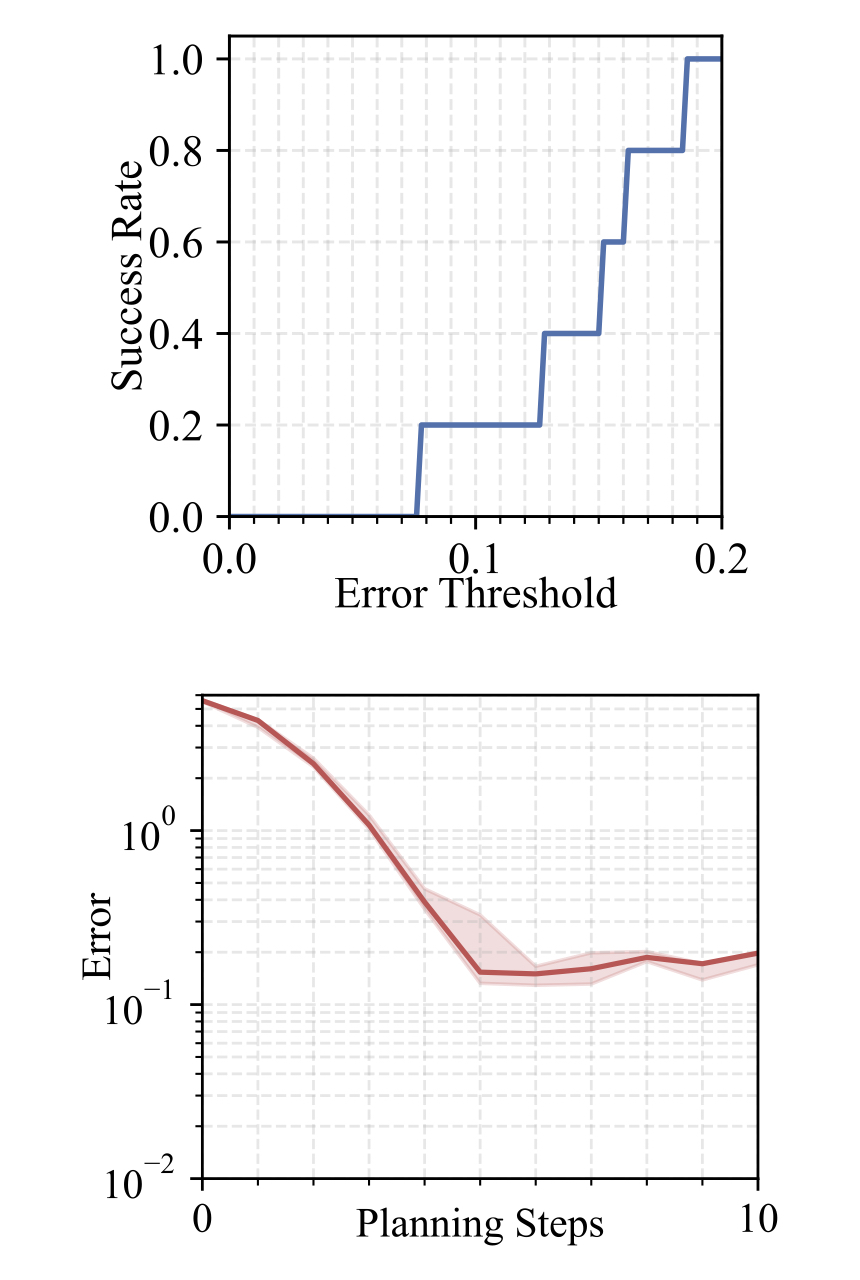
Cloth Relocating
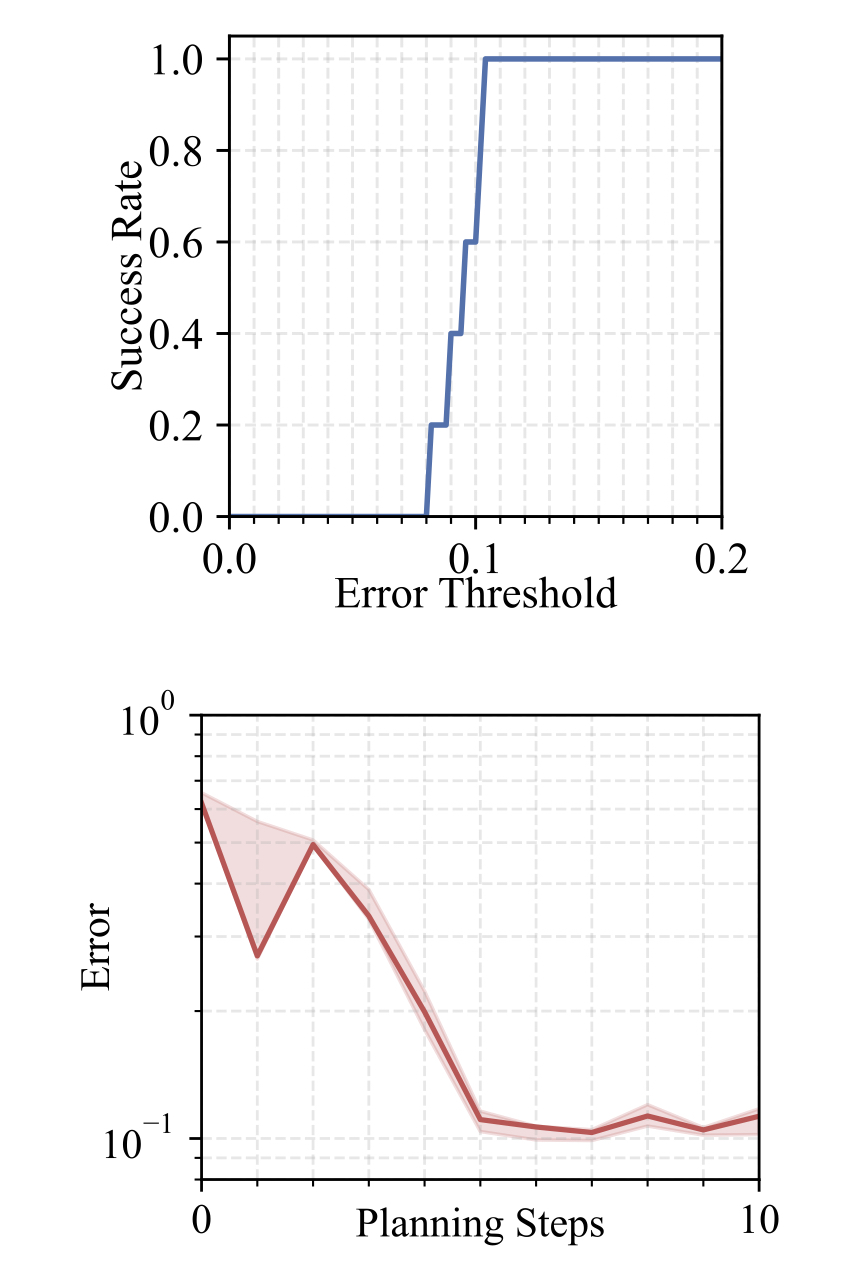
We perform each experiment 5 times and present the results as follows: (i) the median error curve relative to planning steps, with the area between 25 and 75 percentiles shaded, and (ii) the success rate curve relative to error thresholds. Our approach maintains low errors within a limited number of planning steps and achieves a high success rate under a stringent error margin. This demonstrates the effectiveness and precision of our method in handling cloth manipulation tasks.
Generalization Capability (Rebuttal)
Rope for Training and Testing

As our learned models capture the distinct dynamics of objects, the framework provides a decent level of generalization across different instances within the same object category as they share similar dynamics. To demonstrate the capability, we train a dynamics model using the data of a specific rope. We then collect the data of robot interacting with another rope that is unseen for training and visualize the dynamics model prediction on the ground truth, to show that our dynamics model is sufficient to capture the dynamics of ropes and generalize to unseen instances with the actions provided.
Interactive Demos (Rebuttal)
We show 2 videos of the interactive demos of action-conditioned video prediction on rope. Providing the start point and end point of the action, our method predicts the behavior of the rope in the video. At the same time, the demos show that our method is able to predict video of significant object deformations.
Typical Failure Cases of Tracking (Rebuttal)
Our tracking optimization utilize image rendering for supervision. However, for textureless objects with no significant patterns, this approach can result in tracking failures. The gradients from image supervision can not guide the tracking optimization correctly.